TECHNOLOGY TRENDS
Biometric Publication
The term "biometric authentication" refers to the automatic identification, or identity verification, of living individuals using physiological and behavioral characteristics.
To prove you are who you say you are
To prove you are not who you say you are not.
Biometric authentication is the "automatic", "real-time", "non-forensic" subset of the broader field of human identification
These functions are "duals" of each other. In the first function, we really mean the act of linking the presenting person with an identity previously registered, or enrolled, in the system. The user of the biometric system makes a "positive" claim of identity, which is "verified" by the automatic comparison of the submitted "sample" to the enrolled "template". Clearly, establishing a "true" identity at the time of enrollment must be done with documentation external to any biometric system. The purpose of a positive identification system is to prevent the use of a single identity by multiple people. If a positive identification system fails to find a match between an enrollment template and a submitted sample, a "rejection" results. A match between sample and template results in an "acceptance".
The second function, establishing that you are not someone, or not among a group of people already known to the system, constitutes the largest current use of biometrics: negative "identification". The purpose of a negative identification system is to prevent the use of multiple identities by a single person. If a negative identification system fails to find a match between the submitted sample and all the enrolled templates, an "acceptance" results. A match between the sample and one of the templates results in a "rejection".
A negative claim to identity (establishing that you are not who you say you are not) can only be accomplished through biometrics. For positive identification, however, there are multiple alternative technologies, such as passwords, PINs (Personal Identification Numbers), cryptographic keys, and various "tokens", including identification cards. Both tokens and passwords have some inherent advantages over biometric identification. Security against "false acceptance" of randomly generated impostors can be made arbitrarily high by increasing the number of randomly generated digits or characters used for identification. Further, in the event of a "false rejection", people seem to blame themselves for PIN errors, blame the token for token errors, but blame the system for biometric errors. In the event of loss or compromise, the token, PIN, password or key can be changed and reissued, but a biometric measure cannot. Biometric and alternatively-based identification systems all require a method of "exception handling" in the event of token loss or biometric failure.
However, the use of passwords, PINs, keys and tokens carries the security problem of verifying that the presenter is the authorized user, and not an unauthorized holder. Consequently, passwords and tokens can be used in conjunction with biometric identification to mitigate their vulnerability to unauthorized use. Most importantly, properly designed biometric systems can be faster and more convenient for the user, and cheaper for the administrator, than the alternatives. In our experience, the most successful biometric systems for performing the positive identification have been those aimed at increasing speed and convenience, while maintaining adequate levels of security, such as those of references [1-5].
ROBUSTNESS | DISTINCTIVENESS | ACCESSIBILITY | ACCEPTABILITY | AVAILABILITY
There seems to be virtually no limit to the body parts, personal characteristics and imaging methods that have been suggested and used for biometric identification: fingers, hands, feet, faces, eyes, ears, teeth, veins, voices, signatures, typing styles, gaits and odors. This author’s claim to biometric development fame is a now-defunct system based on the resonance patterns of the human head, measured through microphones placed in the users’ ear canals. Which characteristic is best? The primary concerns are at least five-fold: the robustness, distinctiveness, accessibility, acceptability and availability of the biometric pattern. By robust, we mean repeatable, not subject to large changes. By distinctive, we mean the existence of wide differences in the pattern among the population. By accessible, we mean easily presented to an imaging sensor. By acceptable, we mean perceived as non-intrusive by the user. By available, we mean that some number of independent measures can be presented by each user. The head resonance system scores high on robustness, distinctiveness and availability, and low on accessibility and acceptability.
Let’s compare fingerprinting to hand geometry with regard to these measures. Fingerprints are extremely distinctive, but not very robust, sitting at the very end of the major appendages you use to explore the world. Damaging your fingerprints requires less than a minute of exposure to household cleaning chemicals. Many people have chronically dry skin and cannot present clear prints. Hands are very robust, but not very distinctive. To change your hand geometry, you’d have to hit your hand very hard with a hammer. However, many people (somewhat less than 1 in 100) have hands much like yours, so hand geometry is not very distinctive. Hands are easily presented without much training required, but most people initially misjudge the location of their fingerprints, assuming them to be on the tips of the fingers. Both methods require some "real-time" feedback to the user regarding proper presentation. Both fingerprints and the hand are accessible, being easily presented. In the 1990 Orkand study [7], only 8% of customers at Department of Motor Vehicle offices who had just used a biometric device agreed that electronic fingerprinting "invades your privacy". Summarizing the results of a lengthy survey, the study rated the public acceptance of electronic fingerprinting at 96%. To our knowledge, there is no comparable polling of users regarding hand geometry, but we hypothesize that the figures would not be too different. With regard to availability, our studies have shown that a person can present at least 6 nearly-independent fingerprints, but only one hand geometry (your left hand may be a near mirror image of your right).
What about eye-based methods, such as iris and retinal scanning? Eyes are very robust. Humans go to great effort, though both the autonomic and voluntary nervous system, to protect the eye from any damage, which heals quickly when it does occur. The eye structure, further, appears to be quite distinctive. On the other hand, the eye is not easy to present, although the Orkand study showed that the time required to present the retina was slightly less than that required for the imaging of a fingerprint. No similar studies exist for iris scanning, but our experience indicates that the time required for presentation is not much different from retinal scanning. Proper collection of an iris scan requires a well-trained operator, a cooperative subject, and well-controlled lighting conditions. Regarding acceptability, iris scanning is said to have a public acceptance rate of 94%. The Orkand study [8] found a similar rate of acceptability for retinal scanning. The human has two irises for presentation. The question of retina availability is complicated by the fact that multiple areas of the retina can be presented by moving the eye in various directions
CLARIFYING APPLICATIONS
Cooperative versus Non-cooperative
The first partition is "cooperative/non-cooperative". This refers to the behavior of the "wolf", (bad guy or deceptive user). In applications verifying the positive claim of identity, such as access control, the deceptive user is cooperating with the system in the attempt to be recognized as someone s/he is not. This we call a "cooperative" application. In applications verifying a negative claim to identity, the bad guy is attempting to deceptively not cooperate with the system in an attempt not to be identified. This we call a "non-cooperative" application. Users in cooperative applications may be asked to identify themselves in some way, perhaps with a card or a PIN, thereby limiting the database search of stored templates to that of a single claimed identity. Users in non-cooperative applications cannot be relied on to identify themselves correctly, thereby requiring the search of a large portion of the database. Cooperative, but so-called "PIN-less", verification applications also require search of the entire database
Overt versus Covert
The second partition is "overt/covert". If the user is aware that a biometric identifier is being measured, the use is overt. If unaware, the use is covert. Almost all conceivable access control and non-forensic applications are overt. Forensic applications can be covert. We could argue that this second partition dominates the first in that a wolf cannot cooperate or non-cooperate unless the application is overt.
Habituated versus Non-habituated
The third partition, "habituated/non-habituated", applies to the intended users of the application. Users presenting a biometric trait on a daily basis can be considered habituated after short period of time. Users who have not presented the trait recently can be considered "non-habituated". A more precise definition will be possible after we have better information relating system performance to frequency of use for a wide population over a wide field of devices. If all the intended users are "habituated", the application is considered a "habituated" application. If all the intended users are "non-habituated", the application is considered "non-habituated". In general, all applications will be "non-habituated" during the first week of operation, and can have a mixture of habituated and non-habituated users at any time thereafter. Access control to a secure work area is generally "habituated". Access control to a sporting event is generally "non-habituated".
Attended versus Non-attended
A fourth partition is "attended/unattended", and refers to whether the use of the biometric device during operation will be observed and guided by system management. Non-cooperative applications will generally require supervised operation, while cooperative operation may or may not. Nearly all systems supervise the enrollment process, although some do not [4].
Standard Environment
A fifth partition is "standard/non-standard operating environment". If the application will take place indoors at standard temperature (20o C), pressure (1 atm.), and other environmental conditions, particularly where lighting conditions can be controlled, it is considered a "standard environment" application. Outdoor systems, and perhaps some unusual indoor systems, are considered "non-standard environment" applications.
Public Versus Private
A sixth partition is "public/private". Will the users of the system be customers of the system management (public) or employees (private)? Clearly attitudes toward usage of the devices, which will directly effect performance, vary depending upon the relationship between the end-users and system management.
Open versus Closed
A seventh partition is "open/closed". Will the system be required, now or in the future, to exchange data with other biometric systems run by other management? For instance, some State social service agencies want to be able to exchange biometric information with other States. If a system is to be open, data collection, compression and format standards are required.This list is open, meaning that additional partitions might also be appropriate. We could also argue that not all possible partition permutations are equally likely or even permissible.
EXAMPLES OF CLASSIFICATION OF APPLICATIONS
Every application can be classified according to the above partitions. For instance, the positive biometric identification of users of the Immigration and Naturalization Service’s Passenger Accelerated Service System (INSPASS) [3], currently in place at Kennedy, Newark, Los Angeles, Miami, San Francisco, Vancouver and Toronto airports for rapidly admitting frequent travelers into the United States, can be classified as a cooperative, overt, non-attended, non-habituated, standard environment, public, closed application. The system is cooperative because those wishing to defeat the system will attempt to be identified as someone already holding a pass. It will be overt because all will be aware that they are required to give a biometric measure as a condition of enrollment into this system. It will be non-attended and in a standard environment because collection of the biometric will occur near the passport inspection counter inside the airports, but not under the direct observation of an INS employee. It will be non-habituated because most international travelers use the system less than once per month. The system is public because enrollment is open to any frequent traveler into the United States. It is closed because INSPASS does not exchange biometric information with any other system.
The biometric identification of motor vehicle drivers for the purpose of preventing the issuance of multiple licenses can be classified as a non-cooperative, overt, attended, non-habituated, standard environment, public, open application. It is non-cooperative because those wishing to defeat the system attempt not to be identified as someone already holding a license. It is be overt because all are aware of the requirement to give a biometric measure as a condition of receiving a license. It is attended and in a standard environment because collection of the biometric occurs at the licensing counter of a State Department of Motor Vehicles. It is non-habituated because drivers are only required to give a biometric identifier every four or five years upon license renewal. It is public because the system will be used by customers of the Departments of Motor Vehicles. All current systems are closed as States are not presently exchanging biometric information.
CLASSIFYING DEVICES
In last year’s papers at this meeting, I argued that biometric devices were based primarily on either behavioral or physiological measures and could be classified accordingly. The consensus among the research community today is that all biometric devices have both physiological and behavioral components. Physiology plays a role in all technologies even those, such as speaker and signature recognition, previously classified as "behavioral".
The underlying physiology must be presented to the device. The act of presentation is a behavior. For instance, the ridges of a fingerprint are clearly physiological, but the pressure, rotation and roll of the finger when presented to the sensor is based on the behavior of the user. Fingerprint images can be influenced by past behavior, such as exposure to caustic chemicals, as well. Clearly, all biometric devices have a behavioral component and behavior requires cooperation. A technology is incompatible with non-cooperative applications to the extent that the measured characteristic can be controlled by behavior.
THE GENERIC BIOMETRIC SYSTEM
Although these devices rely on widely different technologies, much can be said about them in general. Figure 1 shows a generic biometric authentication system, divided into five sub-systems: data collection, transmission, signal processing, decision and data storage. We will consider these subsystems one at a time.
DATA COLLECTION
Biometric systems begin with the measurement of a behavioral/physiological characteristic. Key to all systems is the underlying assumption that the measured biometric characteristic is both distinctive between individuals and repeatable over time for the same individual. The problems in measuring and controlling these variations begin in the data collection subsystem.
The user's characteristic must be presented to a sensor. As already noted, the presentation of any biometric to the sensor introduces a behavioral component to every biometric method. The output of the sensor, which is the input data upon which the system is built, is the convolution of
1) the biometric measure
2) the way the measure is presented
3) the technical characteristics of the sensor
Both the repeatability and the distinctiveness of the measurement are negatively impacted by changes in any of these factors. If a system is to be open, the presentation and sensor characteristics must be standardized to ensure that biometric characteristics collected with one system will match those collected on the same individual by another system. If a system is to be used in an overt, non-cooperative application, the user must not be able to willfully change the biometric or its presentation sufficiently to avoid being matched to previous records
TRANSMISSION
Some, but not all, biometric systems collect data at one location but store and/or process it at another. Such systems require data transmission. If a great amount of data is involved, compression may be required before transmission or storage to conserve bandwidth and storage space. Figure 1 shows compression and transmission occurring before the signal processing and image storage. In such cases, the transmitted or stored compressed data must be expanded before further use. The process of compression and expansion generally causes quality loss in the restored signal, with loss increasing with increasing compression ratio. The compression technique used will depend upon the biometric signal. An interesting area of research is in finding, for a given biometric technique, compression methods with minimum impact on the signal processing subsystem.
If a system is to be open, compression and transmission protocols must be standardized so that every user of the data can reconstruct the original signal. Standards currently exist for the compression of fingerprint (WSQ), facial images (JPEG), and voice data (CELP).
SIGNAL PROCESSING
Having acquired and possibly transmitted a biometric characteristic, we must prepare it for matching with other like measures. Figure 1 divides the signal processing subsystem into three tasks: feature extraction, quality control, and pattern matching.
Feature extraction is fascinating. Our first goal is deconvolve the true biometric pattern from the presentation and sensor characteristics also coming from the data collection subsystem, in the presence of the noise and signal losses imposed by the transmission process. Our second, related goal is to preserve from the biometric pattern those qualities which are distinctive and repeatable, and to discard those which are not or are redundant. In a text-independent speaker recognition system, for instance, we may want to find the features, such as the frequency relationships in vowels, that depend only upon the speaker and not upon the words being spoken. And, we will want to focus on those features that remain unchanged even if the speaker has a cold or is not speaking directly into the microphone. There are as many wonderfully creative mathematical approaches to feature extraction as there are scientists and engineers in the biometrics industry. You can understand why such algorithms are always considered proprietary. Consequently, in an open system, the "open" stops here.
In general, feature extraction is a form of non-reversible compression, meaning that the original biometric image cannot be reconstructed from the extracted features. In some systems, transmission occurs after feature extraction to reduce the requirement for bandwidth.
After feature extraction, or maybe even before or during, we will want to check to see if the signal received from the data collection subsystem is of good quality. If the features "don't make sense" or are insufficient in some way, we can conclude quickly that the received signal was defective and request a new sample from the data collection subsystem while the user is still at the sensor. The development of this "quality control" process has greatly improved the performance of biometric systems in the last few short years. On the other hand, some people seem never to be able to present an acceptable signal to the system. If a negative decision by the quality control module cannot be over-ridden, a "failure to enroll" error results.
The feature "sample", now of very small size compared to the original signal, will be sent to the pattern matching process for comparison to one or more previously identified and stored features. The term "enrollment" refers to the placing of that feature "sample" into the database for the very first time. Once in the database and associated with an identity by external information (provided by the enrollee or others), the feature sample is referred to as the "template" for the individual to which it refers.The purpose of the pattern matching process is to compare a presented feature sample to a stored template, and to send to the decision subsystem a quantitative measure of the comparison. An exception is enrollment in systems allowing multiple enrollments. In this application, the pattern matching process can be skipped. In the cooperative case where the user has claimed an identity or where there is but a single record in the current database (which might be a magnetic stripe card), the pattern matching process only makes a comparison against a single stored template. In all other cases, the pattern matching process compares the present sample to multiple templates from the database one-at-a-time, as instructed by the decision subsystem, sending on a quantitative "distance" measure for each comparison.
For simplification, we will assume closely matching patterns to have small "distances" between them. Distances will rarely, if ever, be zero as there will always be some biometric, presentation, sensor or transmission related difference between the sample and template from even the same person.
DECISION
The decision subsystem implements system policy by directing the database search, determine "matches" or "non-matches" based on the distance measures received from the pattern matcher, and ultimately make an "accept/reject" decision based on the system policy. Such a policy could be to declare a match for any distance lower than a fixed threshold and "accept" a user on the basis of this single match, or the policy could be to declare a match for any distance lower than a user-dependent, time-variant, or environmentally-linked threshold and require matches from multiple measures for an "accept" decision. The policy could be to give all users, good-guys and bad-guys alike, three tries to return a low distance measure and be "accepted" as matching a claimed template. Or, in the absence of a claimed template, the system policy could be to direct the search of all, or only a portion, of the database and return a single match or multiple "candidate" matches. The decision policy employed is a management decision that is specific to the operational and security requirements of the system. In general, lowering the number of false non-matches can be traded against raising the number of false matches. The optimal system policy in this regard depends both upon the statistical characteristics of the comparison distances coming from the pattern matcher and upon the relative penalties for false match and false non-match within the system. In any case, in the testing of biometric devices, it is necessary to decouple the performance of the signal processing subsystem from the policies implemented by the decision subsystem.
STORAGE
The remaining subsystem to be considered is that of storage. There will be one or more forms of storage used, depending upon the biometric system. Feature templates will be stored in a database for comparison by the pattern matcher to incoming feature samples. For systems only performing "one-to-one" matching, the database may be distributed on magnetic stripe cards carried by each enrolled user. Depending upon system policy, no central database need exist, although in this application a centralized database can be used to detect counterfeit cards or to reissue lost cards without re-collecting the biometric pattern.
The database will be centralized if the system performs one-to-N matching with N greater than one, as in the case of identification or "PIN-less" verification systems. As N gets very large, system speed requirements dictate that the database be partitioned into smaller subsets such that any feature sample need only be matched to the templates stored in one partition. This strategy has the effect of increasing system speed and decreasing false matches at the expense of increasing the false non-match rate owing to partitioning errors. This means that system error rates do not remain constant with increasing database size and identification systems do not linearly scale. Consequently, database partitioning strategies represent a complex policy decision. Scaling equations for biometric systems are given in [8]
If it may be necessary to reconstruct the biometric patterns from stored data, raw (although possibly compressed) data storage will be required. The biometric pattern is generally not reconstructable from the stored templates. Further, the templates themselves are created using the proprietary feature extraction algorithms of the system vendor. The storage of raw data allows changes in the system or system vendor to be made without the need to re-collect data from all enrolled users.
TESTING
Testing of biometric devices requires repeat visits with multiple human subjects. Further, the generally low error rates mean that many human subjects are required for statistical confidence. Consequently, biometric testing is extremely expensive, generally affordable only by government agencies. Few biometric technologies have undergone rigorous, developer/vendor-independent testing to establish robustness, distinctiveness, accessibility, acceptability and availability in "real-world" (non-laboratory) applications. Over the last four years, the U.S. National Biometric Test Center has been focusing on developing lower cost testing alternatives, including testing methods using operational data and methods of generalizing results from a single test for performance prediction over a variety of application-specific decision policies
Application Dependancy of Test Results
All test results must be interpreted in the context of the test application and cannot be translated directly to other applications. Most prior testing has been done in cooperative, overt, habituated, attended, standard environment, private, closed application of the test laboratory. This is the application most suited to decision policies yielding low error rates and high user acceptability. Clearly, people who are habitually cooperating with an attended system in an indoor environment with no data transmission requirements are the most able to give clear, repeatable biometric measures. Habituated volunteers, often "incentivized" employees (or students) of the testing agency, may be the most apt to see biometric systems as acceptable and non-intrusive.
Performance of a device at an outdoor amusement park [4] to assure the identity of non-transferable season ticket holders, for instance, cannot be expected to be the same as in the laboratory. This use constitutes a cooperative, overt, non-habituated, unattended, non-standard environment, public, closed application. Performance in this application can only be predicted from measures on the same device in the same application. Therefore, as a long-term goal in biometric testing, we should endeavor to establish error rates for devices in as many different application categories as possible.
DISTANCE DISTRIBUTIONS
The most basic technical measures which we can use to determine the distinctiveness and repeatability of the biometric patterns are the distance measures output by the signal processing module. Through testing, we can establish three application-dependent distributions based on these measures. The first distribution is created from distance measures resulting from comparison of samples to like templates. We call this the "genuine" distribution. It shows us the repeatability of measures from the same person. The second distribution is created from the distance measures resulting from comparison of templates from different enrolled individuals. We call this the "inter-template" distribution. The third distribution is created from the distance between samples to non-like templates. We call this the "impostor" distribution. It shows us the distinctiveness of measures from different individuals. A full mathematical development of these concepts is given in [9].
These distributions are shown as Figure 2. Both the impostor and inter-template distributions lie generally to the right of the genuine distribution. The genuine distribution has a second "mode" (hump). We have noticed this in all of our experimental data. This second mode results from match attempts by people that can never reliably use the system (called "goats" in the literature) and by otherwise biometrically-repeatable individuals that cannot use the system successfully on this particular occasion. All of us have days that we "just aren’t ourselves". Convolution of the genuine and inter-template curves in the original space of the measurement, under the template creation policy, results in the impostor distribution. The mathematics for performing this convolution is discussed in [10]
If we were to establish a decision policy by picking a "threshold" distance, then declaring distances less than the threshold as a "match" and those greater to indicate "non-match", errors would inevitably be made because of the overlap between the genuine and impostor distributions. No threshold could cleanly separate the genuine and impostor distances. In a perfect system, the repeatability (genuine) distribution would be disjoint (non-overlapping) from the impostor distribution. Clearly, decreasing the difficulty of the application category will effect the genuine distribution by making it easier for users to give repeatable samples, thus moving the genuine curve to the left and decreasing the overlap with the impostor distribution. Movement of the genuine distribution also causes secondary movement in the impostor distribution, as the latter is the convolution of the inter-template and genuine distributions. We currently have no quantitative methodology or predicting movement of the distributions under varying applications.
In non-cooperative applications, it is the goal of the deceptive user ("wolf") not to be identified. This can be accomplished by willful behavior, moving a personal distribution to the right and past a decision policy threshold. We do not know for any non-cooperative system the extent to which "wolves" can move genuine measures to the right.
Some systems have strong quality-control modules and will not allow poor images to be accepted. Eliminating poor images by increasing the "failure to enroll" rate can decrease both false match and false non-match rates. Two identical devices can give different ROC curves based on the strictness of the quality-control module.
We emphasize that, with the exception of arbitrary policies of the quality control module, these curves do not depend in any way upon system decision policy, but upon the basic distinctiveness and repeatability of the biometric patterns in this application. This leads us to the idea that maybe different systems in similar applications can be compared on the basis of these distributions. Even though there is unit area under each distribution, the curves themselves are not dimensionless, owing to their expression in terms of the dimensional distance. We will need a non-dimensional number, if we are to compare two unrelated biometric systems using a common and basic technical performance measure.
NON DIMENSIONAL MEASURES OF COMPARISON
The most useful method for removing the dimensions from the results shown in Figure 2 is to integrate the "impostor" distribution from zero to an upper bound, t. The value of the integral represents the probability that an impostor’s score will be less than the decision threshold, t. Under a threshold-based decision policy, this area represents the probability of a single comparison "false match" at this threshold.
We can then integrate the "genuine" distribution from this same bound, t, to infinity, the value of this integral representing the probability that a genuine score will be greater than the decision threshold. This area represents the probability of a single comparison "false non-match" at this threshold.
These two values, "false match" and "false non-match", for every t, can be displayed as a point on a graph with the false match on the abscissa (x-axis) and the false non-match on the ordinate (y-axis). We have done this in Figure 3 for four Automatic Fingerprint Identification System (AFIS) algorithms tested against a standard database. For historic reasons, this is called the "Receiver Operating Characteristic" or ROC curve [11-13]. Mathematical methods for using these measured false match and false non-match rates for "false acceptance" and "false rejection" prediction under a wide range of system decision policies have been established in [8].
Other measures have been suggested for use in biometric testing [19], such as "D-prime"[20,21] and "Kullback-Leibler" [22] values. These are single, scalar measures, however, and are not translatable to error rate prediction.
We end this section by emphasizing that all of these measures are highly dependent upon the category of the application and the population demographics and are related to system error rates only through the decision policy. Nonetheless, false match and false non-match error rates, as displayed in the ROC curve, seem to be the only appropriate test measures allowing for even rudimentary system error performance prediction.
FIGURE 3
Methods for establishing error bounds on the ROC are not well understood. Each point on the ROC curve is calculated by integrating "genuine" and "impostor" distributions between zero and some threshold, t. Traditionally, as in [14], error bounds for the ROC at each threshold, t, have been found through a summation of the binomial distribution. The confidence, b , given a non-varying probability p, of K sample/template comparison scores, or fewer, out of N independent comparison scores being in the region of integration would be
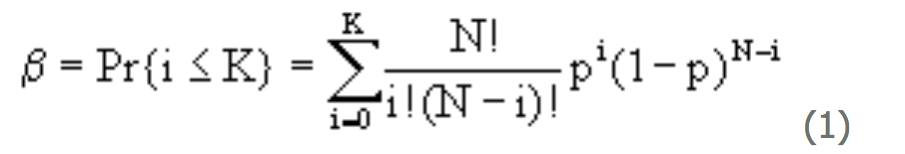
Here, the exclamation point, called "factorial", indicates that we multiply together all integers from 1 to the number indicated. For instance, 3!=1x2x3=6. This number gets so huge so fast that 120! is too big for precise computation on most PCs. In most biometric tests, values of N and K are too large to allow N! and K! in equation (1) to be computed directly. The general procedure is to substitute the "incomplete Beta function" [15,16] for the cumulative binomial distribution on the right hand side above, then numerically invert to find p for a given N, K, and b .
This equation can be used to determine the required size of a biometric test for a given level of confidence, if the error probability is known in advance. Of course, the purpose of the test is to determine the error probability, so, in general, the required number of comparison scores (and test subjects) cannot be predicted prior to testing. To deal with this, "Doddington’s Law" is to test until 30 errors have been observed. If the test is large enough to produce 30 errors, we will be about 95% sure that the "true" value of the error rate for this test lies within about 40% of that measured [17].
Equation (1) will not be applicable to biometric systems if: 1) trials are not independent; 2) the error probability varies across the population. If cross-comparisons (all samples compared to all templates except the matching one) are used to establish the "impostor distribution", the comparisons will not be independent and (1) will not apply. An equation for error bounds in this case has been given by Bickel [18]. The varying error probability across the population ("goats" with high false non-match errors and "sheep" with high false match errors) similarly invalidates (1) as an appropriate equation for developing error bounds. Developing appropriate equations for error bounds under "real-world" conditions of non-independence of the comparisons and non-stationarity of the error probabilities is an important part of our current research.
The real tragedy in the break-down of equation (1) is in our inability to predict even approximately how many tests will be required to have "statistical confidence" in our results. We currently have no way of accurately estimating how large a test will be necessary to adequately characterize any biometric device in any application, even if error rates are known in advance.
In any case, we jokingly refer to error bounds as the "false sense of confidence interval" to emphasize that they refer to the statistical inaccuracy of a particular test owing to finite test size. The bounds in no way relate to future performance expectations for the tested device, due to the much more significant uncertainty regarding user population and overall application differences. We do not report error bounds or "confidence levels" in our testing.
ORGANISATIONAL TESTING
Given the expense of assembling and tracking human test subjects for multiple sample submissions over time, and the limited, application-dependent nature of the resulting data, we are forced to ask, "Are there any alternatives to laboratory-type testing?" Perhaps the operational data from installed systems can be used for evaluating performance. Most systems maintain an activity log, which includes transaction scores. These transaction scores can be used directly to create the genuine distribution of Figure 2.
The problem with operational data is in creating the impostor distribution. Referring to Figure 1, the general biometric system stores feature templates in the database and, rarely, compressed samples, as well. If samples of all transactions are stored, our problems are nearly solved. Using the stored samples under the assumption that they are properly labeled (no impostors) and represent "good faith" efforts to use the system (no players, pranksters or clowns), we can compare the stored samples with non-like templates, in "off-line" computation, to create the impostor distribution.
Unfortunately, operational samples are rarely stored, due to memory restrictions. Templates are always stored, so perhaps they can be used in some way to compute the impostor distribution. Calculating the distance distribution between templates leads to the inter-template distribution of Figure 2. Figure 2 was created using a simulation model based on biometric data from the Immigration and Naturalization Service Passenger Accelerated Service System (INSPASS) used for U.S. immigration screening at several airports. It represents the relationship between genuine, impostor and inter-template distributions for this 9-dimensional case. Clearly, the inter-template distribution is a poor proxy for the impostor distribution. Figure 4 shows the difference in ROC curves resulting from the two cases.
Currently, we are not technically capable of correcting ROCs developed from inter-template distributions. The correction factors depend upon the template creation policy (number of sample submissions for enrollment) and more difficult questions, such as the assumed shape of the genuine distribution in the original template space [9].
TEST POPULATION
So how can we design a test to develop a meaningful ROC and related measures for a device in a chosen application for a projected population? We need to start by collecting "training" and "test" databases in an environment that closely approximates the application and target population. This also implies taking training and test samples at different times to account for the time-variation in biometric characteristics, presentations and sensors. A rule of thumb would be to separate the samples at least by the general time of healing of that body part. For instance, for fingerprints, 2 to 3 weeks should be sufficient. Perhaps, eye structures heal faster, allowing image separation of only a few days. Considering a hair cut to be an injury to a body structure, facial images should perhaps be separated by one or two months.
A test population with stable membership over time is so difficult to find, and our understanding of the demographic factors effecting biometric system performance is so poor, that target population approximation will always be a major problem limiting the predictive value of our tests.
The ROC measures will be developed from the distributions of distances between samples created from the test data and templates created from the training data. Distances resulting from comparisons of samples and templates from the same people will be used to form the genuine distribution. Distances resulting from comparison of samples and templates from different people will be used to form the impostor distribution
As explained above, we have no way to really determine the number of distance measures needed for the required statistical accuracy of the test. Suppose that, out of desperation, we accept equation (1) as an applicable approximation. One interesting question to ask is "If we have no errors, what is the lowest false non-match error rate that can be statistically established for any threshold with a given number of comparisons?". We want to find the value of p such that the probability of no errors in N trials, purely by chance, is less than 5% . This is called the "95% confidence level". We apply equation 1 using X=0,
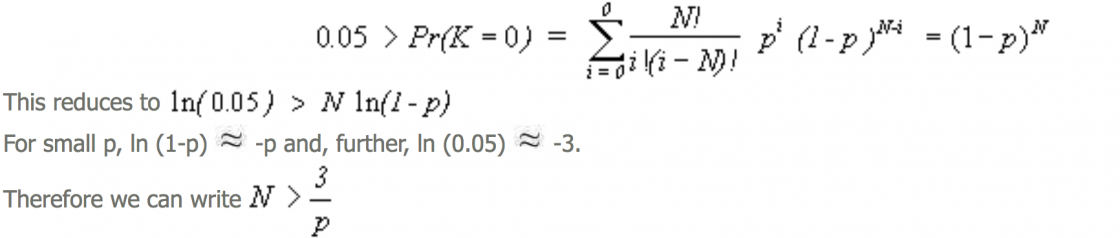
This means that at 95% statistical confidence, error rates can never be shown to be smaller than three divided by the number of independent tests. For example, if we wish to establish false non-match error rates to be less than one in one hundred (0.01), we will need to conduct 300 independent tests with no errors (3/300 = 0.01). Conducting 300 independent tests of will require 300 samples and 300 templates, a total of 600 patterns. Again, all of this analysis rests upon the questionable validity of the assumptions used to create equation (1).
We might ask, at this point, if it is necessary to have that many test users, or if a small number of users, each giving many samples, might be equivalent. Unfortunately, we require statistically "independent" samples, and no user can be truly independent from him/herself. Technically, we say that biometric data is "non-stationary", meaning that a data set containing one sample from each of one thousand users has different statistical properties than a data set containing one thousand samples from a single user. Ideally, we would require for our tests N different users, each giving one sample. In practice, we may have to settle for as many users as practicable, each giving several samples separated by as much time as possible. The impact of this on system performance prediction is also not known.
AVAILABLE TEST RESULTS
Most past tests have reported "false acceptance" and "false rejection" error rates based on a single or variable system policy. The U.S. National Biometric Test Center has advocated separating biometric performance from system decision policy, by reporting device "false match/ false non-match" rates, allowing users to estimate rejection/acceptance rates from these figures. We point out that some systems (access control) will "accept" a user if a match is found, while other systems (social service and driver’s licensing) will "reject" a user if a match is found (during enrollment). Device false match/ false non-match performance may be the same in each system, but the decision policy will invert the measures of "false acceptance" and "false rejection". The reporting of results as a dimension-less Receiver Operating Characteristic (ROC) curve is becoming standard.
Results of some excellent tests are publicly available. The most sophisticated work has been done on speaker verification systems. Much of this work is extremely mature, focusing on both the repeatability of sounds from a single speaker and the variation between speakers [24-30]. The scientific community has adopted general standards for speech algorithm testing and reporting using pre-recorded data from a standardized "corpus" (set of recorded speech sounds), although no fully satisfactory corpus for speaker verification systems currently exists. Development of a standardized database is possible for speaker recognition because of the existence of general standards regarding speech sampling rates and dynamic range. The testing done on speech-based algorithms and devices has served as a prototype for scientific testing and reporting of biometric devices in general.
In 1991, the Sandia National Laboratories released an excellent and widely available comparative study on voice, signature, fingerprint, retinal and hand geometry systems [31]. This study was of data acquired in a laboratory setting from professional people well-acquainted with the devices. Error rates as a function of a variable threshold were reported, as were results of a user acceptability survey. In April, 1996, Sandia released an evaluation of the IriS can prototype [32] in an access-control environment.
A major study of both fingerprinting and retinal scanning, using people unacquainted with the devices and in a non-laboratory setting, was conducted by the California Department of Motor Vehicles and the Orkand Corporation in 1990 [7]. This report measured the percentage of acceptance and rejection errors against a database of fixed size, using device-specific decision policies, data collection times, and system response times. Error results cannot be generalized beyond this test. The report includes a survey of user and management acceptance of the biometric methods and systems.
The Facial Recognition Technology (FERET) Program has produced a number of excellent papers [33-36] since 1996, comparing facial recognition algorithms against standardized databases. This project was initially located at the U.S. Army Research Laboratory, but has moved now to NIST. This study uses as data facial images collected in a laboratory setting. Earlier reports from this same project included a look at infrared imagery as well [37].
In 1998, San Jose State University released the final report to the Federal Highway Administration [38] on the development of biometric standards for the identification of commercial drivers. This report includes the results of an international automatic fingerprint identification system benchmark test.
The existence of CardTech/SecurTech, in addition to other factors such as the general growth of the industry, has encouraged increased informal reporting of test results. Recent reports have included the experiences of users in non-laboratory settings [1-5].
CONCLUSION
The science of biometrics, although still in its infancy, is progressing extremely rapidly. Just as aeronautical engineering took decades to catch up with the Wright brothers, we hope to eventually catch up with the thousands of system users who are successfully using these devices in a wide variety of applications. The goal of the scientific community is to provide tools and test results to aid current and prospective users in selecting and employing biometric technologies in a secure, user-friendly, and cost-effective manner.
BIBLIOGRAPHY
[1] Gail Koehler, "Biometrics: A Case Study – Using Finger Image Access in an Automated Branch", Proc. CTST’98, Vo. 1, pg. 535-541
[2] J.M. Floyd, "Biometrics at the University of Georgia", Proc. CTST '96, pg 429-230
[3] Brad Wing, "Overview of All INS Biometrics Projects", Proc. CTST’98, pg. 543-552
[4] Presentation by Dan Welsh and Ken Sweitzer, of Ride and Show Engineering, Walt Disney World, to CTST’97 , May 21, 1997.
[5] Elizabeth Boyle, "Banking on Biometrics", Proc.CTST’97, pg. 407-418
[6] D. Mintie, "Biometrics for State Identification Applications – OperationalExperiences", Proc. CTST’98, Vol. 1, pg. 299-312
[7] Orkand Corporation, "Personal Identifier Project: Final Report", April 1990, State of California Department of Motor Vehicles report DMV88-89, reprinted by the U.S. National Biometric Test Center.
[8] J.L. Wayman, "Error Rate Equations for the General Biometric System", IEEE Automation and Robotics Magazine, March 1999
[9] J.L. Wayman, "Technical Testing and Evaluation of Biometric Identification Devices" in A. Jain, etal (eds), Biometrics: Personal Identification in a Networked Society, (Kluwer Academic Press, 1998)
[10] C. Frenzen, "Convolution Methods for Mathematical Problems in Biometrics", Naval Postgraduate School Technical Report, NPS-MA-99-001, January 1999
[11] Green, D.M. and Swets, J.A., Signal Detection Theory and Psychophysics (Wiley, 1966),
[12] Swets, J.A.(ed.), Signal Detection and Recognition by Human Observers (Wiley, 1964)
[13] Egan, J.P., Signal Detection Theory and ROC Analysis, (Academic Press,1975)
[14] W. Shen, etal, "Evaluation of Automated Biometrics-Based Identification and Verification Systems", Proc. IEEE, vol.85, Sept. 1997, pg. 1464-1479.
[15] M. Abromowitz and I. Stegun, "Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables", (John Wiley and Sons, New York, 1972)
[16] W.H. Press, et al, Numerical Recipes, 2nd ed., (Cambridge University Press, Cambridge, 1988)
[17] J. E. Porter, "On the ’30 error’ criterion", ITT Industries Defense and Electronics Group, April 1997, available from the National Biometric Test Center
[18] P. Bickel, response to SAG Problem #97-23, University of California, Berkeley, Department of Statistics.
[19] J. Williams, "Proposed Standard for Biometric Decidability", Proc. CTST'96, pg. 223-234
[20] Peterson, W.W. and Birdsall, T.G., "The Theory of Signal Detectability", Electronic Defense Group, U. of MI., Tech. Report 13 (1954)
[21] Tanner, W.P. and Swets, J.A., "A Decision-Making Theory of Visual Detection", Psychological Review, Vol. 61, (1954), pg. 401-409
[22] S. Kullback and R. Leibler, "On Information and Sufficiency", Annals of Mathematical Statistics, vol.
22, (1951), pg. 79-86
[23] P. Bickel, response to SAG Problem #97-21, University of California, Berkeley, Department of Statistics.
[24] B. Atal, "Automatic Recognition of Speakers from Their Voices", Proc. IEEE, 64, (1976), pg 460-475
[25] A. Rosenberg, "Automatic Speaker Verification", Proc. IEEE, 64, (1976), pg. 475-487
[26] N. Dixon and T. Martin, Automatic Speech and Speaker Recognition (IEEE Press, NY, 1979)
[27] G. Doddington, "Speaker Recognition: Identifying People by Their Voices", Proc. IEEE, 73, (1985), pg 1651-1664
[28] A. Rosenberg and F. Soong, "Recent Research in Automatic Speaker Recognition" in S. Furui and M. Sondhi, eds, Advances in Speech Signal Processing (Marcel Dekker, 1991)
[29] J. Naik, "Speaker Verification: A Tutorial", IEEE Communications Magazine, (1990), pg. 42-48
[30] J.P.Campbell, Jr.,"Speaker Recognition: A Tutorial", Proc. IEEE, vol.85, September 1997, pg. 1437-1463
[31] J.P. Holmes, et al, "A Performance Evaluation of Biometric Identification Devices", Sandia National Laboratories, SAND91-0276, June 1991.
[32] F. Bouchier, J. Ahrens, and G. Wells, "Laboratory Evaluation of the IriScan Prototype Biometric Identifier", Sandia National Laboratories, SAND96-1033, April 1996
[33] P.J. Phillips, et al, "The FERET Evaluation Methodology for Face-Recognition Algorithms", Proc. IEE Conf.on Comp.Vis.and Patt. Recog., San Juan, Puerto Rico, June 1997
[34] S.A. Rizvi, etal, "The FERET Verification Testing Protocol for Face Recognition Algorithms", NIST, NISTIR 6281, October 1998
[35] P.J. Phillips, etal, "The FERET Evaluation" in H. Wechsler, etal (eds) Face Recognition: From Theory to Applications (Springer-Verlag, Berlin, 1998)
[36] P.J. Phillips, "The FERET Database and Evaluation Procedure for Face-Recognition Algorithms", Image and Vision Computing Journal, Vol. 16, No.5, 1998, pg. 295-306
[37] P.J. Rauss, et al, "FERET (Face-Recognition Technology) Recognition Algorithms", Proceedings of ATRWG Science and Technology Conference, July 1996
[38] J.L. Wayman, "Biometric Identifier Standards Research Final Report", October, 1997, sponsored by the Federal Highway Adminstration